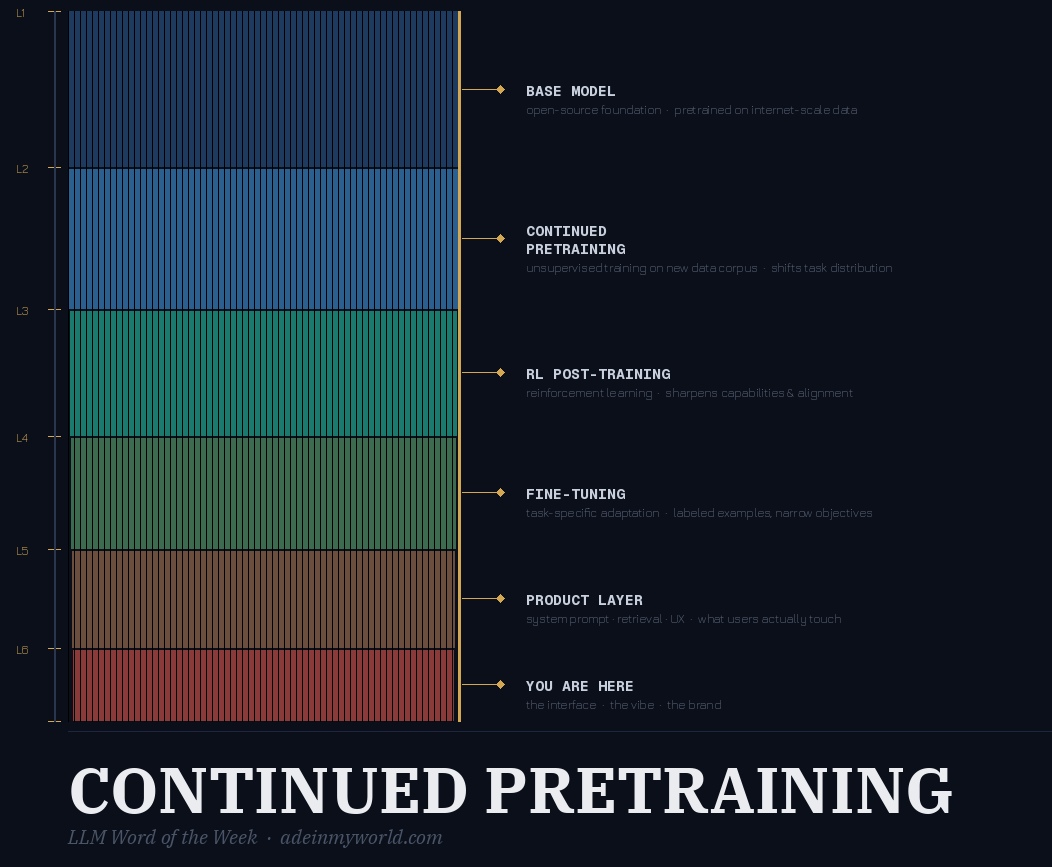
Continued Pretraining is when you take an already-trained base model and train it further on new data before any task-specific tuning. It’s not training from scratch, and it’s not finetuning. It sits in between — a way to reshape a model’s foundational knowledge and capability distribution before you specialize it.
What Cursor didn’t say (TL;DR)
On March 20, 2026, a developer named Fynn was debugging Cursor’s API when the response came back with a model identifier that wasn’t “Composer 2” — it was kimi-k2p5-rl-0317-s515-fast. He tweeted it. 444,000 views.
Cursor had launched Composer 2 just the day before, calling it “frontier-level coding intelligence” and presenting it as evidence that the company is a serious AI research lab. What the announcement omitted was that Composer 2 was built on top of Kimi K2.5, an open-source model from Moonshot AI, a Chinese startup backed by Alibaba and Tencent.
Cursor’s VP of Developer Education Lee Robinson confirmed the connection within hours, acknowledging that Composer 2 started from an open-source base, and that only about a quarter of the compute spent on the final model came from that base — the rest came from Cursor’s own training. Co-founder Aman Sanger called the omission “a mistake” and said future models would be more upfront about it.
Why continued pretraining is different from finetuning
This is the key disambiguation — and the exact technical argument Cursor used to defend themselves.
Finetuning (which we’ve covered) is task-specific adaptation. You take a base model and train it on labeled examples for a narrow job: “summarize this,” “classify this,” “answer questions like this.” It changes behavior, not core capability.
Continued pretraining goes deeper. You run additional unsupervised training on large datasets before any task-specific work. It adjusts the model’s task distribution and capability focus — it determines where subsequent reinforcement learning starts from. The goal isn’t to teach the model a new job — it’s to change what the model fundamentally knows and can do before you specialize it.
Cursor’s argument was essentially: we didn’t just wrap Kimi. We continued pretraining it, then applied 3× as much RL compute on top. The benchmark data supports that the jump from Composer 1.5 to 2 was nearly three times larger than the jump from 1 to 1.5, despite 20× more RL compute already having been invested in the earlier transition — suggesting that continued pretraining, not just RL, provided the capability unlock.
Key things you should know
-
It’s not the same as building from scratch. When a company does continued pretraining on an open-source model, the resulting model inherits significant capability from the upstream base. That’s not inherently wrong — but it matters for provenance and trust.
-
Cursor is not alone. Just two days before the Composer 2 controversy, Rakuten launched “Rakuten AI 3.0” in Japan, which independent analysis revealed to be DeepSeek V3 — with the MIT license file deleted from the distribution. Research shows that six of ten major Japanese AI models are based on either DeepSeek or Alibaba’s Qwen model families, with most companies downplaying or omitting the connection.
-
The disclosure gap is the real story. The controversy wasn’t about Cursor using Kimi K2.5. It was about the framing. When a company announces a significant upgrade without attributing the capability to external technology, users reasonably infer that the capability came from internal work. That inference is what the community felt was wrong.
So — why should engineers and product leaders care now?
Because continued pretraining is how the modern AI product stack actually works — and most people buying AI tools don’t know it. AI coding launches are now judged not only on performance, but on provenance, disclosure, and the visible treatment of upstream work.
When you buy an “in-house” AI model, you’re often buying a base model + continued pretraining + RL + product wrapper. Each of those layers adds value. But they’re not the same thing as building a model from scratch — and conflating them erodes the trust that makes these tools worth paying for.
The company’s self-summarization technique — training the model to compress its own working memory during long-horizon tasks rather than truncating context — is a genuinely novel contribution. But that contribution gets harder to credit properly when it’s bundled inside a launch that obscured its upstream foundation.
Practical takeaways
- Ask “what’s the base?” when evaluating AI tools. This is now a legitimate procurement question, not a gotcha. A capability today can disappear if the provider switches base models tomorrow.
- Understand the training stack. Base model → continued pretraining → finetuning → RL post-training → product layer. Each is a distinct step. Vendors who publish what they did at each step are worth trusting more.
- Continued pretraining is expensive and real. Don’t dismiss a model as “just a wrapper” because it started from an open-source base. The question is how much transformation happened on top — and whether the company is honest about the answer.
Final thought
Cursor’s mistake wasn’t building on Kimi K2.5. Continued pretraining on strong open-source foundations is increasingly how good products get built fast. The mistake was letting users believe the capability came from nowhere. In 2026, your model’s family tree is part of your product. Own it.
Originally published on LinkedIn