LLM Word of the Week: Tokens
When you talk to an AI, it doesn’t see your message as words, it sees tokens.
Think of tokens as the building blocks of language for large language models. They’re not always full words. Sometimes they’re word pieces, punctuation, or even spaces.
What’s A Token (TL;DR)
Tokens are the currency of thought for LLMs. They’re how language becomes math, how meaning becomes something a model can compute.
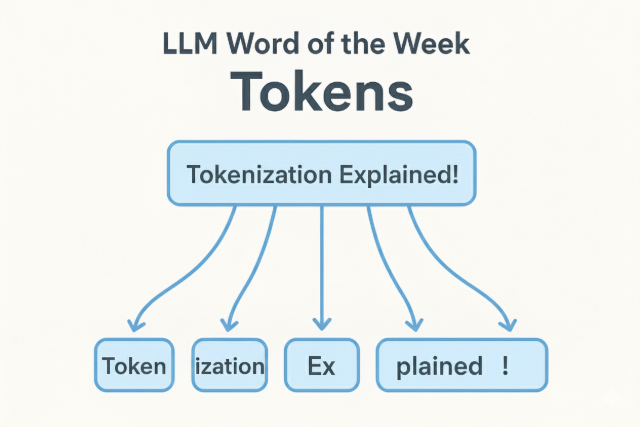
For example:
“Explain tokenization like I'm five”might become
["Ex", "plain", "token", "iza", "tion", "like", "I", "'", "five"]
Each of those pieces is a token.
Why tokens matter
Everything the model does; reading, reasoning, responding, etc. happens one token at a time. That’s also how usage and cost are measured: you pay (and wait) per token processed.
So when you hear things like “The model can handle 200k tokens”, that’s describing the size of its context window, or how many tokens it can juggle in one conversation.
Why tokenization isn’t trivial
Different tokenizers split text differently. English, emojis, or code all get broken up in unique ways, which means two identical-looking prompts might actually cost different token counts.
This also means that fine-tuning, embedding generation, and even RAG depend on consistent tokenization - otherwise, your “meaning units” don’t line up and the model understanding is all over the place
Final thoughts
If context window define how much a model can remember, tokens define what exactly it remembers.
Together, they shape how LLMs read, reason, and respond, one chunk at a time.
Or put simply:
Tokens are how AI breaks human language into bite-sized chunks of understanding.
Try this tokenizer
If you want to play with a small, fun tokenizer that breaks your text into colorful tokens, try the live demo: Try the simple tokenizer. It opens a playful page where you can type up to 50 characters and watch the tokens and counts update in real time.